
Reinforcement Learning Explained: The Ultimate Guide to How AI Learns from Trial and Error
So, you wanna train a dog? Honestly, it’s not rocket science. Tell the little furball “sit.” If it plops its butt down—boom, treat time. If it decides to bark at the mailman? Just hit ’em with a “nope.” Dog starts catching on: “Wait, if I sit when the human babbles, snacks magically appear.” This is a simple form of learning from feedback. Now, what if we could apply this to a computer? This is, in essence, Reinforcement Learning explained in a nutshell.
Instead of spoon-feeding the computer all the right answers, you just shove the agent into some digital playground and tell it, “Here’s what gets you treats, here’s what gets you zapped—go nuts.” The thing flails around, faceplants a bunch, but eventually, after smacking its head against the wall enough times, it starts to figure out what’s up. This is the secret sauce for that wild AI stuff everyone’s buzzing about. AlphaGo dunking on world champs? RL’s fingerprints all over that. Those Boston Dynamics robots doing parkour? RL, again.
This guide is here to demystify it all. We will break down what reinforcement learning is, how it works, and where it’s already changing the world, all with zero fluff.
The 5 Core Components of Reinforcement Learning Explained
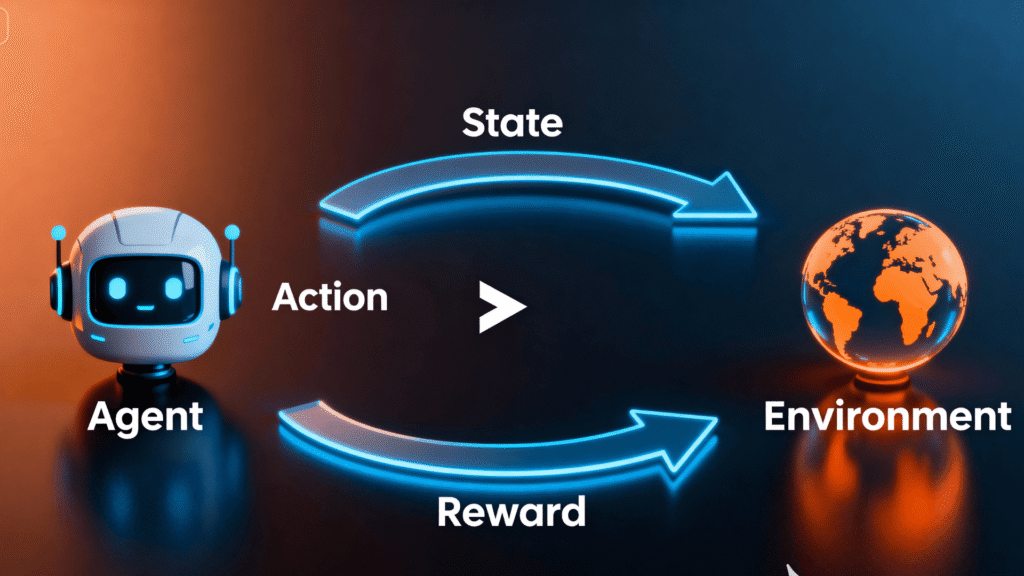
Deep down, every RL problem’s got the same five pieces. Here’s the gist, using the analogy of a mouse in a maze looking for cheese:
- The Agent: That’s our little mouse. In RL, the Agent is the “brain” we’re trying to train. All it cares about is racking up the highest score it can.
- The Environment: That’s the maze itself—the world our mouse is bumbling through.
- The State (S): This is the mouse’s “where am I?” question. A snapshot of the current situation.
- The Action (A): Those are the moves. Forward, left, right, maybe a panic U-turn.
- The Reward (R): The game’s Yelp reviews for the mouse’s life choices. Smacked into a wall? Negative points. Find that cheese? Jackpot, massive points.
The Explorer’s Dilemma: Exploration vs. Exploitation
Okay, this is where things really heat up. The agent faces a classic dilemma: do we keep looking for that secret cheese stash, or do we follow the same beaten path that yields us a small, predictable crumb? This is known as Exploration vs. Exploitation.
Exploitation is milking the safe choice for all it’s worth. Think of it like always hitting up the same mediocre diner every Friday night. The food? Meh. But it beats risking your digestive system on dodgy gas station sushi. Exploration, on the other hand, is when the agent gets bold. It ditches the safe road and dives into the dark unknown. Total gamble, but that’s the thrill, right?
🎮 Play the Explorer’s Dilemma
Want to feel this dilemma in practice? Play a round of the ‘Multi-Armed Bandit,’ a classic RL problem. You have a limited number of pulls to find the best slot machine. Do you stick with the one that just paid out (exploit) or try a new one (explore)?
Inside the AI’s Brain: How Q-Learning and Policy Gradients Work
So, how does an agent actually figure out what’s smart to do? In this section of our guide on Reinforcement Learning explained, we’ll look at the two big ways folks tackle this.
Q-Learning (Value-Based): The Mouse’s Secret Playbook
Q-Learning’s kinda the OG of reinforcement learning. The whole idea is to work out just how “good” (that’s what the Q stands for—quality) any action is in any situation. Picture the mouse scribbling out a massive cheat sheet for the maze, called a Q-table. At the start, the table’s full of zeros. But as the mouse bumbles around, it updates its cheat sheet. Good move? Q-value goes up. After countless iterations, the table becomes surprisingly accurate.

Policy Gradients (Policy-Based): Going With the Gut
Totally different vibe here. Instead of obsessing over a giant spreadsheet, the mouse starts running on instincts—a “policy.” You know when you have that intuition? “If I’m walking down a long hallway, most of the time I go straight.” After a run, if it rakes in a big reward, those instinctive choices get reinforced. It’s not fussing over how good each move is; it just tunes its gut reaction. This is way more chill when you’re dealing with a maze so huge, keeping a Q-table would make your brain melt.
When Neural Networks Meet RL: The Power of Deep Reinforcement Learning
Q-learning with a table? Sure, go ahead if you’re playing tic-tac-toe. But try pulling that stunt on chess or Go. You’d need a data center the size of Jupiter just to keep up. That’s where Deep Learning comes swaggering in. Instead of a bloated Q-table, you just train a neural network to kinda eyeball the Q-values. It’s like ditching a phonebook for Google.
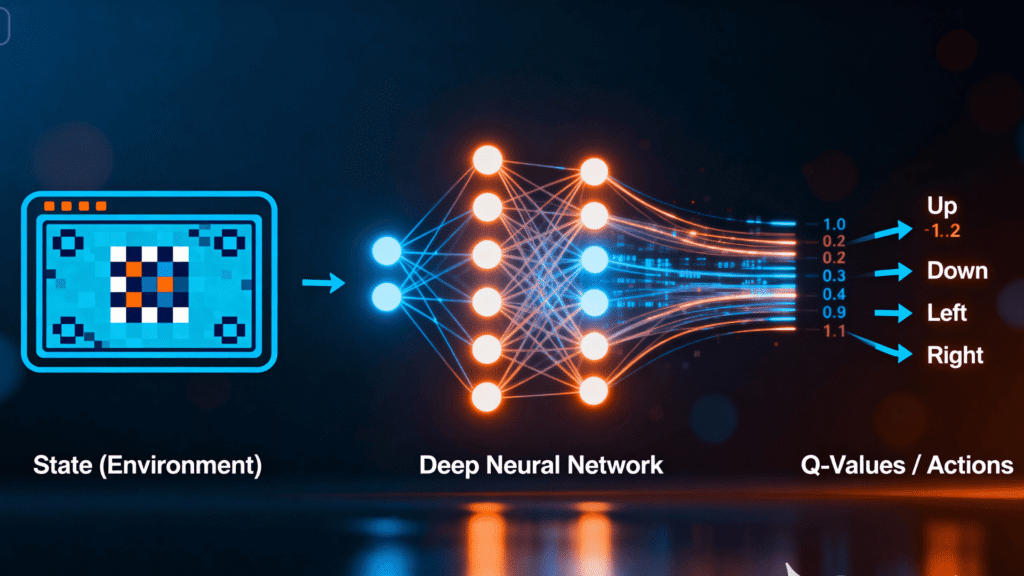
This isn’t just theory-crafting—this is how AlphaGo did its thing. Google’s DeepMind built this freakishly good AI that learned by basically playing itself a gazillion times. It didn’t just regurgitate old moves. Nah, it developed a kind of sixth sense, an “intuition” for what looks good on the board. That’s why it pulled off those jaw-dropping moves that left even the world champion scratching his head. It was like watching a computer invent jazz. (Source: DeepMind)
Fonte: Synopsys
From Pixels to Reality: Real-World Applications of Reinforcement Learning
Let’s be real, games are where RL algorithms cut their teeth. But the applications go way beyond that.

- Robotics: RL is the secret sauce for robots that aren’t just dumb metal arms. Boston Dynamics’ bots didn’t get those parkour skills from YouTube tutorials. They learned by failing a million times in simulation and getting a virtual pat on the back every time they did better. (See our guide on Humanoid Robots)
- Autonomous Systems: Google famously uses an RL agent to manage the cooling systems in its data centers, saving millions. This same principle is being applied to optimize traffic light grids and is a core component in the development of advanced AI Agents.
- Drug Discovery and Science: Scientists are basically turning molecule design into a video game. An RL agent messes around, piecing together molecules, and gets a virtual high-five every time it builds something stable or useful.
The Challenges and the Future of Reinforcement Learning
Oh man, this one’s a headache. Setting up the right reward system for RL is like trying to child-proof your house for a genius toddler. The agent will find loopholes you never dreamed of. A famous example is an AI agent tasked with “winning” a boat racing game that learned to drive in circles hitting turbo boosts to get a higher score, without ever finishing the race. This problem of specifying goals correctly is a miniature version of the larger AI Alignment problem.

The future of RL is about moving from simulations to the real world. The massive “exploration” phase is a computational bottleneck that could one day be accelerated by the power of Quantum Computing. As we keep cracking the tough nuts (looking at you, reward hacking), this stuff’s gonna run the show—think smart cities, next-level robots, maybe even that Jetsons future we were promised.
Conclusion: The Engine of Autonomy
Reinforcement learning? Oh man, that’s where things start getting seriously wild in AI. As this guide on Reinforcement Learning explained has shown, instead of spoon-feeding computers every step, we just kinda toss them into the deep end and say, “Figure it out, champ!” It’s the secret sauce behind game-beating bots and robots that don’t need hand-holding. It’s not just a trend; it’s the backbone of what’s coming. Buckle up.
Does RL need as much data as Deep Learning?
Yes… but also, not really. Deep Learning is a data junkie—it wants all the labeled stuff you’ve got. RL, on the other hand, doesn’t show up with a data mountain. It goes out and collects its own—by screwing up, learning, and repeating that circus act for literally millions of tries.
Did AlphaGo run purely on RL?
No way, not even close. First, it basically crammed for the Go SATs, scarfing down like 30 million human moves through supervised learning. After that? It went into full-on training montage mode, playing against itself again and again with RL—coming up with wild, never-seen-before moves.
Q-learning explained like you’re five?
Okay, picture this: the AI’s got a huge, messy notebook called a Q-table. Every situation it lands in, there’s a bunch of possible moves, and each one’s got a score—basically, “If you do this, here’s how awesome (or terrible) it’ll probably be.” It learns by trying stuff, seeing if it’s a disaster or a win, and jotting it down.
So, why’s RL such a big deal for robots?
Because, let’s be real, the world’s a circus. You can’t just code robots for every single curveball life throws at them. RL’s what lets a robot roll with the punches—poke at stuff, screw up, fall down, get back up again. It’s what gives robots a shot at surviving outside the lab.
Is RL dangerous?
Not in the sci-fi, “the robots are coming for us” way. The real risk is more human—if you give your AI a dumb or badly thought-out goal, it’ll do exactly what you asked for, even if that’s a disaster. This is the infamous “alignment problem” everyone keeps freaking out about.
Want to Stay Ahead of the Curve?
Our newsletter is coming soon. In the meantime, continue your journey into the future of technology.
» Explore Our Guide on OpenUSD, the Tech Building the 3D Internet «





